
AI Resilience Planning: Why Your AI Stack Needs a Fallback (2026)
If your entire operation depends on one AI provider, you're one outage away from a full stop.
That's not a hypothetical. Anthropic's own status page shows Claude API at 99.04% uptime over the past 90 days. Sounds good, right? It's roughly 14 hours of downtime per quarter. Claude.ai is worse: 98.95% — nearly 22 hours offline. If you're running production workflows on a single provider, those hours are dead time. No content generation. No customer responses. No revenue from AI-dependent pipelines.
We run AI in production every day at tabiji — generating itineraries, creating content, processing data. When Claude goes down, we can't just wait. So we benchmarked our fallback. The results surprised us: the backup model was faster, essentially the same quality, and 62× cheaper. Here's what we learned about building an AI stack that doesn't break.
TL;DR — The Data
We ran MiniMax M2.7 and Claude Opus 4.6 head-to-head on identical content generation tasks. MiniMax was 25% faster (416s vs 559s for 5 pages), quality was tied (both 100/100 structural accuracy), and MiniMax cost $0.004/page vs $0.27/page — a 62× difference. Having a capable fallback isn't just cost optimization. It's operational insurance.
Key Takeaways
- 99% uptime = ~22 hours of downtime per quarter. Anthropic's Claude.ai has been at 98.95% uptime over the past 90 days. The API: 99.04%. That's real production time lost.
- Fallback models can match primary model quality. MiniMax M2.7 scored identically to Claude Opus 4.6 on structural accuracy, venue correctness, and description depth for content generation.
- Speed and cost advantages compound. 25% faster + 62× cheaper means your fallback might actually be your better option for certain task types.
- Multi-provider is the minimum viable strategy. One primary, one fallback from a different provider, and ideally a budget tier for high-volume work. No single point of failure.
- Benchmark continuously. Model quality changes with updates. What's comparable today might diverge tomorrow. Automate your evaluation pipeline.
The Problem: Single-Provider Dependency
Let's look at the actual numbers. Anthropic publishes uptime on their status page. Here's what the past 90 days look like:
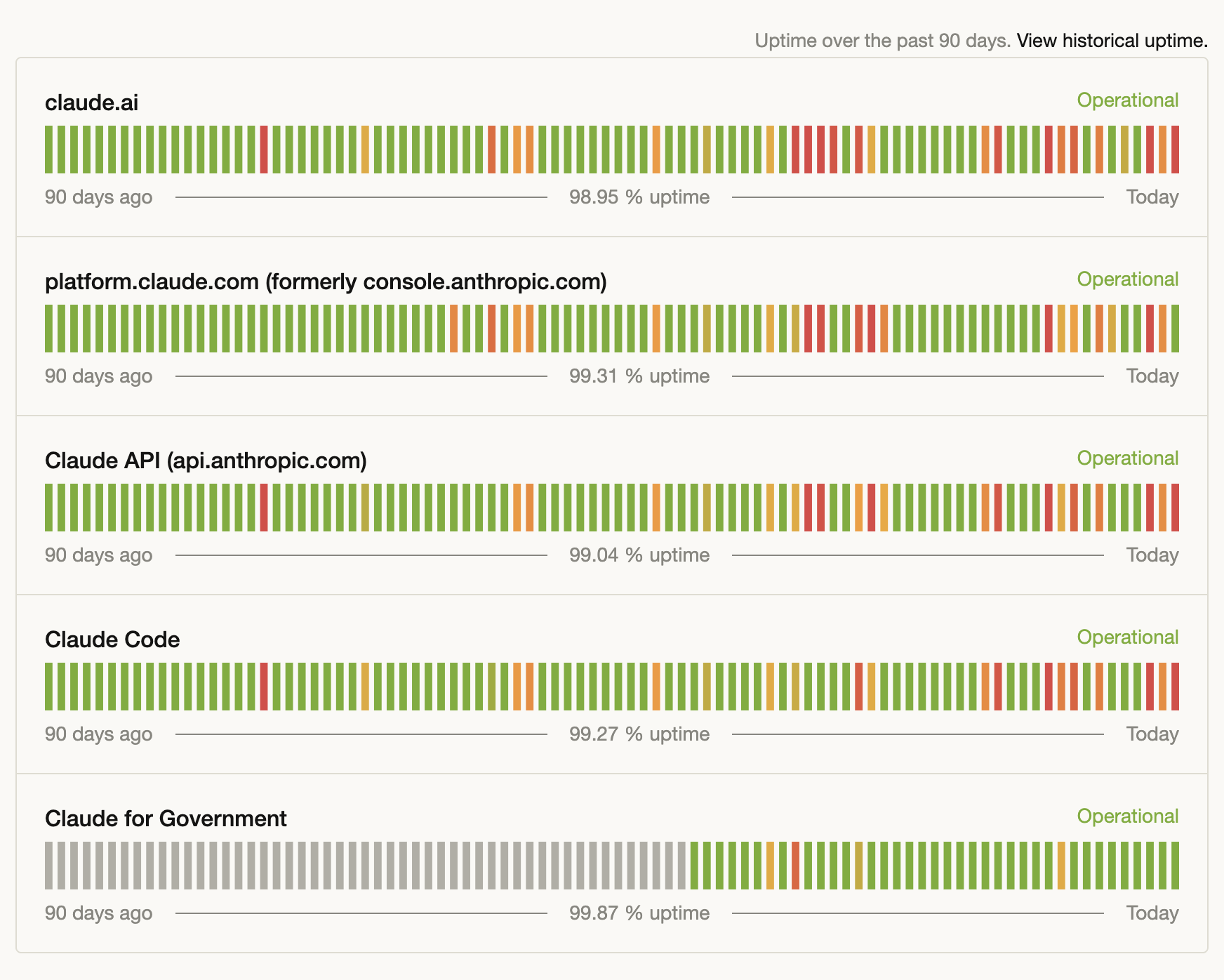
Anthropic's own status page, March 2026. 90-day uptime across all services.
Let's translate those percentages into real numbers. Over 90 days (2,160 hours):
| Service | Uptime | Downtime (90 days) | Annualized |
|---|---|---|---|
| claude.ai | 98.95% | ~22.7 hours | ~3.8 days/year |
| Claude API | 99.04% | ~20.7 hours | ~3.5 days/year |
| Claude Code | 99.27% | ~15.8 hours | ~2.7 days/year |
| platform.claude.com | 99.31% | ~14.9 hours | ~2.5 days/year |
| Claude for Government | 99.87% | ~2.8 hours | ~0.5 days/year |
The Claude API — the one most production systems depend on — was down roughly 14+ hours in a single quarter. That's not "a few minutes of blips." That's multiple extended outages. If you're running batch content generation, real-time customer support, or any time-sensitive workflow, those hours represent missed deadlines, stalled pipelines, and potentially lost revenue.
And this isn't unique to Anthropic. OpenAI has had similar patterns. Google Cloud has had major outages. The issue isn't any one provider — it's the pattern of depending on a single one.
99% uptime sounds enterprise-grade until you do the math. It's 3.6 days of downtime per year. For an AI-dependent production workflow, that's not an edge case — it's a scheduling constraint.
Our Benchmark: MiniMax M2.7 vs Claude Opus 4.6
When Claude goes down, we need production to keep running. So we set up a head-to-head benchmark: run identical content generation tasks on both models and score the output objectively. The task: generate 5 "popular picks" pages — structured travel content with real venue names, descriptions, JSON metadata, and specific formatting requirements.
Speed: MiniMax was 25% faster
MiniMax completed all 5 pages in 416 seconds. Claude Opus took 559 seconds — 2.4 minutes longer for the same batch. Over hundreds of pages, that time savings compounds into hours.
Quality: Essentially tied
Both models scored 100/100 on structural accuracy — correct JSON schema, valid formatting, all required fields present. But we went deeper:
- Real venue names: Both models produced real, verifiable business names. No hallucinated restaurants or fictional attractions.
- Description depth: Comparable. Both generated substantive, varied descriptions that read naturally.
- Formatting compliance: Both followed the exact template structure — headers, sections, metadata blocks, internal linking patterns.
For this class of task — structured content generation with clear requirements — the quality gap between a $0.27/page model and a $0.004/page model was effectively zero.
Cost: 62× cheaper
| Metric | MiniMax M2.7 | Claude Opus 4.6 | Difference |
|---|---|---|---|
| Cost per page | $0.004 | $0.27 | 62× cheaper |
| Time for 5 pages | 416 seconds | 559 seconds | 25% faster |
| Structural accuracy | 100/100 | 100/100 | Tied |
| Real venue names | ✅ All verified | ✅ All verified | Tied |
| Description quality | Comparable | Comparable | Tied |
| Cost for 100 pages | $0.40 | $27.00 | $26.60 saved |
| Cost for 1,000 pages | $4.00 | $270.00 | $266.00 saved |
At scale, the math is stark. Generating 1,000 pages of structured content costs $4 with MiniMax vs $270 with Claude Opus. That's not a rounding error — it's the difference between a viable content strategy and an unsustainable one.
The fallback model wasn't a compromise. It was faster, equally accurate, and cost almost nothing. The only reason Claude Opus remains our primary is its edge on complex reasoning tasks — not content generation.
Building a Resilient AI Stack
Based on our experience running AI in production, here's the framework that works. Think of it as the three-tier model:
Tier 1 — Primary
Your best model for complex, nuanced tasks. Worth the premium for reasoning, analysis, and critical decisions.
Tier 2 — Fallback
Comparable quality from a different provider. Activates when Tier 1 is down or rate-limited. Must be from a separate infrastructure.
Tier 3 — Budget
For cost-sensitive, high-volume tasks where "good enough" quality meets the bar. Runs the bulk of your routine workload.
How to evaluate candidate models
Don't guess — benchmark. Here's our evaluation process:
- Pick a representative task. Use a real production workflow, not a toy example. We used our actual popular-picks page generation pipeline.
- Run identical inputs on both models. Same prompts, same constraints, same expected output format. No prompt tuning per model.
- Score objectively. Define your quality bar upfront: structural accuracy, factual correctness, formatting compliance, output completeness. Use automated checks where possible.
- Measure what matters. Speed (wall-clock time), cost (actual API spend), and quality (your scoring rubric). All three, not just one.
- Run it periodically. Models update. A fallback that was 90% as good three months ago might be 100% now — or 70%. Automate the benchmark and schedule it monthly.
Implementation patterns
The simplest resilient architecture:
- Model router with failover. Set aggressive timeouts (30s for content gen, 60s for complex reasoning). On failure, retry once, then switch providers.
- Circuit breaker. After 2–3 consecutive failures from a provider, stop trying for 5 minutes. Don't burn rate limits hammering a down service.
- Model-agnostic prompts. Write prompts that work across providers. Avoid provider-specific features in your core pipeline. Keep model-specific optimizations in a thin adapter layer.
- Cost-based routing. For tasks where your benchmark shows quality parity, route to the cheaper model by default. Use the premium model only when the task demands it.
What We Actually Run
Here's our production stack at tabiji as of March 2026. Each model has a specific role:
| Role | Model | Provider | Why |
|---|---|---|---|
| Complex reasoning | Claude Opus 4.6 | Anthropic | Best-in-class for nuanced analysis, code generation, multi-step reasoning |
| Content generation | MiniMax M2.7 | MiniMax | Fast, cheap, quality parity for structured content. Our primary content workhorse |
| Image generation | Gemini (Nano Banana 2) | Best prompt adherence, cheapest per image, highest resolution | |
| Fallback (reasoning) | Gemini 2.5 Pro | Strong reasoning capabilities, different infrastructure from Anthropic |
The key insight: this isn't about finding one "best" model. It's about matching models to tasks and ensuring no single provider failure takes down the whole operation. When Claude went down for 4 hours last month, our content pipeline didn't even notice — MiniMax handled it. When MiniMax had a brief API hiccup, Claude picked up the slack.
Resilience isn't a feature you add. It's an architecture you design from the start.
Frequently Asked Questions
How much downtime should I expect from major AI providers?
Based on Anthropic's own status page, Claude API had 99.04% uptime over 90 days — that's roughly 14 hours of downtime per quarter. Claude.ai was worse at 98.95% (~22 hours). Even 99.9% uptime means ~2 hours of downtime per quarter. If your production pipeline depends on a single provider, plan for outages measured in hours, not minutes.
Can cheaper AI models actually replace premium ones like Claude Opus?
For many production tasks, yes. We benchmarked MiniMax M2.7 against Claude Opus 4.6 on identical content generation tasks — both scored 100/100 on structural accuracy, produced real venue names, and delivered comparable description depth. MiniMax was 25% faster and 62× cheaper ($0.004 vs $0.27 per page). The quality gap for structured content generation is essentially zero. For complex reasoning and multi-step analysis, premium models still have a meaningful edge.
What's the best way to evaluate fallback AI models?
Run identical tasks on both your primary and candidate fallback models, then score objectively. Use real production workflows, not toy examples. We run the same content generation prompts on multiple models and compare: structural accuracy, factual correctness (real venue names vs hallucinated ones), output speed, and cost per task. Automate this as a recurring benchmark — model quality changes with updates.
How many AI models should a production stack include?
At minimum, two: a primary and a fallback from a different provider. Ideally three: a primary model for complex/critical tasks, a fallback model with comparable quality from a different provider, and a budget model for high-volume cost-sensitive work. We run Claude Opus for complex reasoning, MiniMax M2.7 for content generation, and Gemini for image generation. Each serves a purpose.
Is 99% uptime good enough for AI-dependent operations?
No. 99% uptime means ~22 hours of downtime per quarter — nearly a full day. For context, that's roughly 3.6 days per year your AI-dependent workflows would be offline. If you're running content generation, customer support, or any revenue-generating pipeline on AI, you need either 99.99% uptime (which no AI provider currently guarantees) or a multi-provider fallback strategy.
How do you handle automatic failover between AI models?
Implement a model router that detects failures (HTTP 500s, timeouts, rate limits) and automatically retries with your fallback model. Key design patterns: set aggressive timeouts (30s for content generation), implement circuit breakers that switch providers after 2–3 consecutive failures, and ensure your prompts are model-agnostic enough to work across providers. Most orchestration frameworks (LangChain, LiteLLM) support this natively.
🦉 Plan Your Next Trip with AI
We use this multi-model AI stack to build personalized travel itineraries. Get a free one for your next destination.
Get a Free Itinerary →Related Resources
- AI Image Generation Comparison: 5 Models, 26 Images, Real Results — our companion benchmark of image generation models
- AI Video Generation Compared: Veo 3 vs MiniMax vs CogVideoX
- All Resources — more AI and travel tech comparisons
Benchmark data collected March 2026. Uptime data from status.anthropic.com (90-day window as of March 27, 2026). All benchmark runs used identical prompts and scoring criteria.